It’s a well-known fact that around 95% of all new ideas fail.
From Colgate’s foray into frozen kitchen entrees in the 1980s to Heinz’s memorable “EZ Squirt'' colored ketchup, not even the largest brands are immune to spectacular failures. But it’s not just products; new advertisements, branding, logos, and messaging can all similarly fall victim.
So why is the rate of failure so high? And what can you do to mitigate your risks? Often, the answer is simple: know your audience.
While there are a variety of reasons why an idea may not succeed, poor decision making and lack of market orientation can be large drivers. Both of which stem from a brand not quite understanding what their audience loves, and what they could do without. This is precisely where concept testing comes into play.
What is Concept Testing?
At its core, concept testing is the process of evaluating an idea to better understand how it will be received by consumers before it hits the market.
Concept tests allow you to ask consumers how they feel about your new idea, providing you with direct feedback on its viability. Not only does the information from concept testing help you avoid costly mistakes, but the insights gleaned can also help you further develop your idea and go-to-market strategy.
While there are various concept testing methods, we will primarily focus on survey tools. If you’re interested in learning about other techniques, find out how to get creative with heatmaps.
Why is Concept Testing Important and What are the Benefits?
Concept testing plays a major role in the trajectory of a new idea, providing insights and eliminating the risks associated with sub-par market research. While your team might think their latest idea is genius, the opinions of your target audience are the only opinions that truly matter.
If they don’t see the value in your idea during testing, they definitely won’t see the value once it’s released.
Here are some benefits of concept testing:
_Size=sm)_Color=Success.png) Better understand consumers likes or dislikes to adjust your concepts accordingly. You can repeat this process until you hone in on the best possible version of your idea.
Better understand consumers likes or dislikes to adjust your concepts accordingly. You can repeat this process until you hone in on the best possible version of your idea.
Eliminate the time you would have wasted chasing the production of a poor concept.
Because most concept tests can be done via online survey platforms there is a high degree of flexibility. This means you can easily gather feedback on many facets of your idea, from pricing to style, allowing you to perfect every last detail before release.
Types of Concept Testing
Comparison Testing
Comparison testing is exactly what you'd expect. Respondents are shown two or more concepts and compare them by simply selecting their favorite or using ranking or rating-scales questions.
The results of a comparison test are often clear and simple to understand. Which makes it easy to determine which of your concepts is the winner.
But comparison tests aren't without drawbacks. One major issue is a lack of context. Comparison testing gives you little insight into why one concept was selected over the others.
Monadic Testing
With monadic testing, your sample (pool of respondents) is separated into groups. Each group sees only one concept, meaning there is no comparison, simply an in-depth evaluation of the concept shown.
Because respondents are only shown a single concept, this method makes it possible to get in-depth insights without the drawbacks of a lengthy survey. So instead of simply understanding which concept won, you can better understand how consumers feel about the elements of each.
But, once again, there are some drawbacks. To break respondents into groups you'll need a larger sample size, which can drive up your cost and time-to-insights.
Sequential Monadic Testing
Much like monadic testing, sequential monadic testing also requires you to split your audience into groups. But instead of only showing one concept to each group, respondents evaluate all of your concepts in random order. Each group is asked the same follow-up questions at the end of the rotation.
As each group evaluates all of the concepts, the required sample size for a sequential monadic test is smaller- reducing costs. It also allows you to test multiple concepts in a single round, making it quite efficient.
But, as you guessed it, this methodology isn't foolproof. Because respondents see all of your concepts, the survey length can be long. This ultimately affects the completion rate and can even cause respondent fatigue- which leads to poor data quality.
Proto-monadic Testing
As the name might suggest, proto-monadic testing is a combination of sequential monadic and comparison testing. This method has respondents examine multiple concepts and then choose the one they prefer.
Ultimately proto-monadic testing allows you to confirm that the winner of your comparison test is compatible with the in-depth insights gained on individual concepts.
When Should I Run a Concept Test?
Ideally, you should run a concept test for any major new idea or change to your products, pricing, services, or messaging. All kinds of challenges can be solved or averted entirely with the right kinds of research.
Generally, businesses use concept testing to compare new products, pricing, or brand messaging. However, the benefits of concept testing are not unique to these circumstances. Here are a few other scenarios where a concept test could be helpful:
Further Develop Ideas
So you like your idea, but what about your target audience? By running a simple concept test, you can utilize valuable consumer insights to tweak and perfect your idea, ultimately upping the likelihood of breakout success.
Eliminate Poor Ideas
While it may seem like a given, you can learn quite a bit from eliminating low-potential ideas. Often you can learn why these ideas fell flat with your audience so that you can avoid making similar mistakes in the future.
Identify High-Potential Consumer Segments
Who is most enthusiastic about your idea, and why? By finding out which consumer segments are likely to purchase your product, and their reasons for doing so, you can more easily identify the ideal market(s) for your idea.
Perfect the Marketing Strategy
Once you’ve identified your high-potential consumer segments, you can also learn what makes your idea valuable to them, whether it be specific features or pricing. With that knowledge, you can remove the guesswork from your marketing and meet your audience on their terms.
How to Run a Concept Test
Running your concept test doesn’t have to be difficult, but it is important to follow a few best practices:
Gather Stakeholders
To kick off the process, meet with the relevant stakeholders to brainstorm all of the concepts you would like to test. This meeting is also a great opportunity to set the parameters for your test, such as the number of concepts, sample size, budget, and survey methodology.
Set Specific Goals
Define clear objectives and goals. Think about the purpose of this test and the specific details you’d like to gather from participants. What kind of data would be most helpful for your decision-making process? How are you planning to analyze the data once collected? What kind of response do you want to get? Setting these intentions early on provides a point of reference for all of the stages yet to come.
Choose the Right Methodology
While your sample and the items being tested are often top of mind, the design itself is equally crucial to success. Two of the most popular survey methodologies are monadic testing and sequential monadic testing.
In a monadic test, your target audience is split into multiple groups. Each of these groups is then shown one of the concepts and asked for their opinions on specific features they like or dislike. Because only a single concept is shown per group, you can ask more follow up questions to get in-depth insights without compromising the survey's length. Because the audience is broken down into smaller groups, you will often need a larger sample size, which can raise your cost. However, if you only have a few concepts to test or are not on a tight timeframe, monadic testing might be best for you.
Conversely, sequential monadic testing shows respondents two or more concepts presented in a random order to avoid bias. Each concept is followed by the same correlating questions to gather data. While this type of testing often demands a longer survey length, the sample sizes can be smaller and you can often glean consumer insights from the respondents’ comparisons of each concept. If you have many concepts, limited metrics, or a smaller budget; sequential monadic testing might be right for you.
Build the Survey
At the outset of your survey, make sure to provide participants with some context about what they can expect from the experience. Next, include high-resolution visuals (images or videos) and clear text that describe your concept.
Always present these in a consistent manner to avoid any potential bias. For the questions themselves, refer back to your visuals and text often to remind respondents which concepts you are referencing in each question. Additionally, consider using Likert scales to allow respondents to rank their opinions. Not only does this help to create a consistent structure, but the type of data collected enables automated analysis.
Field the Survey
Depending on the types of concepts you are testing and your available budget, the audience you target may vary. If you’re a smaller company with a low budget simply looking for some initial reactions to your idea, consider fielding your survey to trusted co-workers, connections, and friends. This can be a great (free) way to gather feedback and further develop your idea.
If you are looking to add new features to an existing concept, introduce a new pricing model, or change your branding, field your survey to loyal customers first. While you may still want to send your survey out to a larger population later on, the insights gleaned from your loyal supporters can be extremely valuable.
If you are developing an entirely new concept you will most likely want to choose a sample representative from a survey panel provider. To get the most relevant data, the sample should be representative of your target audience, which will then inform the ideal sample size. For example, if you are interested in learning about a concept’s appeal across the United States, the sample size will need to be large enough to account for the populations across each state. In this scenario, a sample size in the thousands would be most appropriate. Conversely, if you’re interested in learning about the appeal of a concept among millennial females living in Austin, Texas, your sample size can be as small as 200 respondents.
Analyze the Data
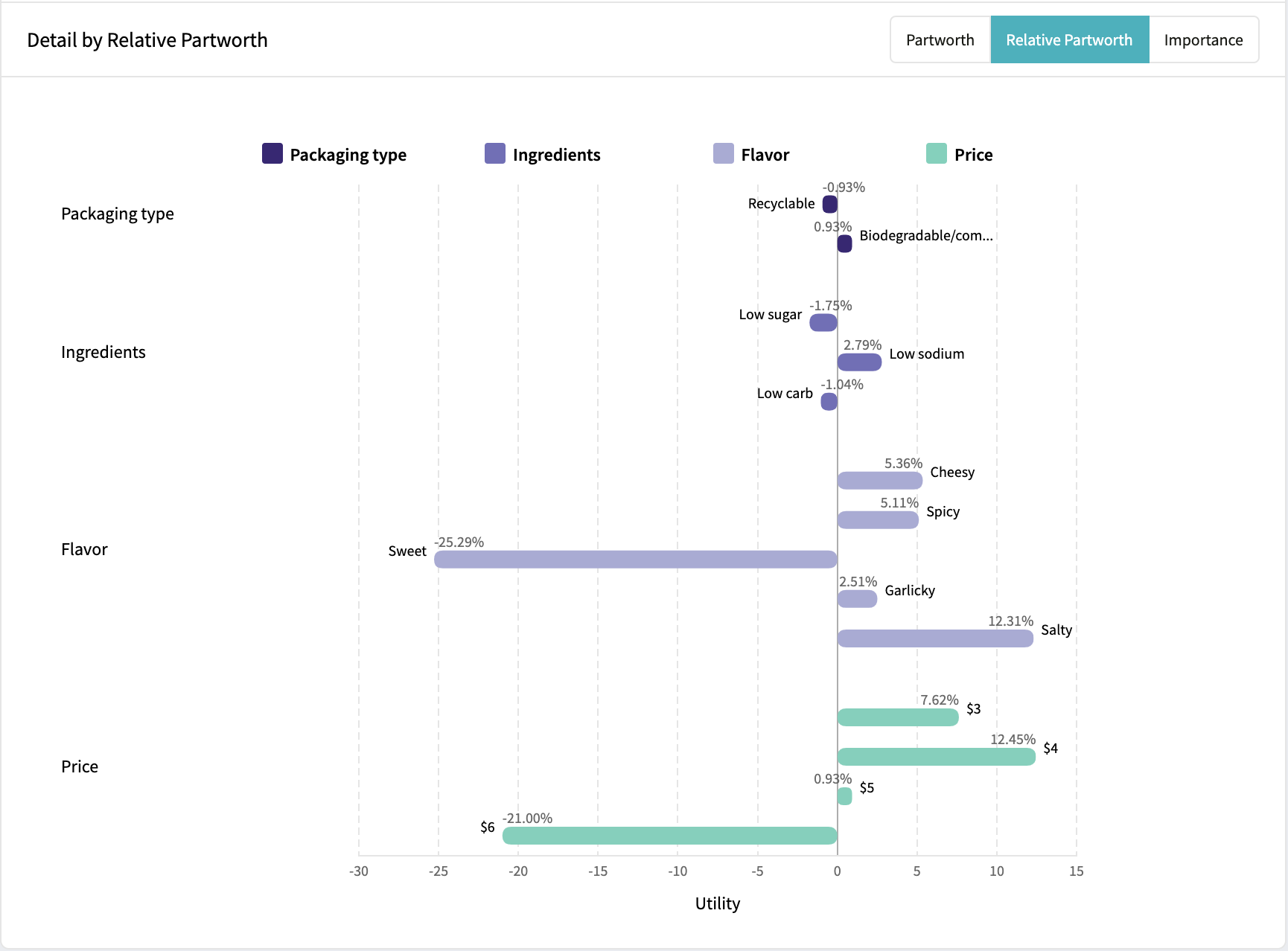
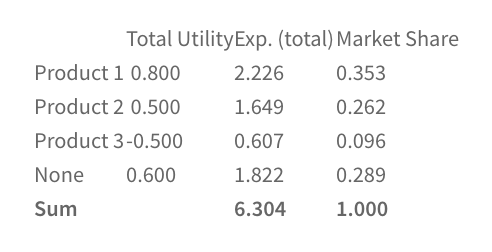
Once you’ve collected all of your responses, it’s time to turn them into insights! The first step is simply ranking the overall performance of each concept. Which performed best overall? What concept was a flop? From there, think of different market segments or groups that are important to your organization. Was their preferred concept different from the overall winner?
From there, you can drill down even deeper to compare the data and filter for variables that are important to you. These can be as simple as demographic variables, like age, gender, or ethnicity. Or, you can filter for "control" variables, like those who eat healthy v.s. those who don't.
As a general tip, think about each of the multiple-choice questions in your survey. Often you can rely on these to filter, compare, and contrast different audiences- allowing you to build personas based on them.
Concept Testing Examples
Concept testing is used by a wide range of companies across many different industries. Some of the most popular examples of concept testing in the real world include:
Bonterra Organic Estates- New Product Concept Test
When our client Bonterra Organic Estates was ready to expand its portfolio with a new ultra-premium tier of wines, their branding team was tasked with creating an entirely new portfolio design.
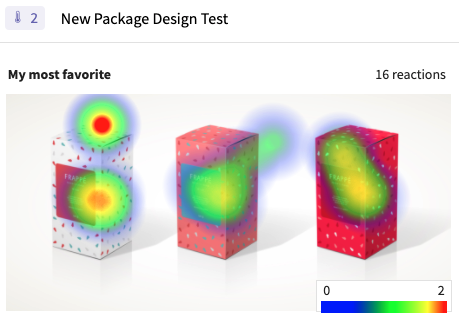
They turned to SightX's concept testing software to compare the new packaging options and dig deeper into the perceptions surrounding each. They also added heat maps to their concept test, allowing them to get detailed feedback on individual elements of each design.
These insights allowed Bonterra's brand team to select and perfect a final concept, launching their new tier with confidence.
Feltman's - Packaging Concept Test
You might recognize our client Feltman's of Coney Island for being the world's first hotdog. But, as their core products grew to gain national recognition, the team set their sights on expansion with plans to release a new bacon product.
Not only would they need to understand how potential customers would consider their new bacon offering, but they simultaneously needed to test different packaging, sizes, and price points.
Using SightX's concept testing features, the Feltman's team was able to gather business-critical insights in less than a day. These insights not only helped them select a winning packaging design but also allowed them to find the ideal packaging size and price for their target market.
Grounded.World- Competitive Concept Testing
When our client Grounded partnered with B Water & Beverages Inc. (who had licensed Brita®) they were tasked with developing the concept for a new bottled water in infinitely recyclable aluminum packaging.
This new product was not only meant to be an eco-friendly alternative to single-use plastic bottles, but it also needed to compete in a crowded premium bottled-water market.
They turned to SightX's concept testing software to test out bottle designs, compare their winning design against competitors in the space, and test messaging for marketing purposes.
The insights from their study led to a packaging design with high appeal and purchase intent that stood out in a crowd. So much so that even though the product hadn't yet been launched, the winning design had the highest purchase intent score across the entire category.
Once the product was launched, they saw major press pickups in outlets like Forbes and a wave of rave customer reviews. But it wasn't just the media and consumers who loved the new product. Retailers also took note, helping Brita sell their newest product into major chains on their very first meeting.
Concept Testing with SightX
The SightX platform is the only tool you'll ever need for concept testing: a single, unified solution for consumer engagement, data collection, advanced analysis, and reporting. While powerful enough for insights teams at Fortune 500 companies, the user-friendly interface makes it simple for anyone to start, optimize, and scale their research.
Plus, with SightX's research team, you can gain access to the best thinking in the insights field. Our in-house experts will guide you through every step in the market research process, from survey scripting to analysis support, and everything in-between.
If you're ready to get started with iterative market research, get started today!





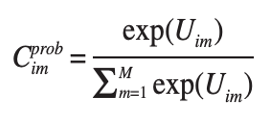


 Tip: Remember to create your scales from low to high (e.g. least important to most important, or disagree to agree, etc.).
Tip: Remember to create your scales from low to high (e.g. least important to most important, or disagree to agree, etc.).